
What’s distributed concensus
基于消息传递通信模型的分布式系统,不可避免地会发生以下错误:进程可能会慢、垮、重启,消息可能会延迟、丢失、重复;在分布式领域中,数据的存储的一致性一直是一个比较核心的问题。
What’s Raft
1990年莱斯利·兰伯特就提出了Paxos算法,奠定了其在分布式一致性方面的地位,但其由于算法自身的复杂性令人望而却步(本人也尝试学习了,…),也很难从系统实现角度发挥作用,目前Zookeeper中采用了Paxos算法。
Raft生来目标就是可理解的一致性算法,在论文In Search of an Understandable Consensus Algorithm (Extended Version) by Diego Ongaro and John Ousterhout 中,其将算法的可理解性摆在了首要的位置。
raft.github.io中有大量学习的资料可供参考。
Raft
Architecture
Replicated state machine architecture. The consensus algorithm manages a replicated log containing state machine commands from clients. The state machines process identical sequences of commands from the logs, so they produce the same outputs.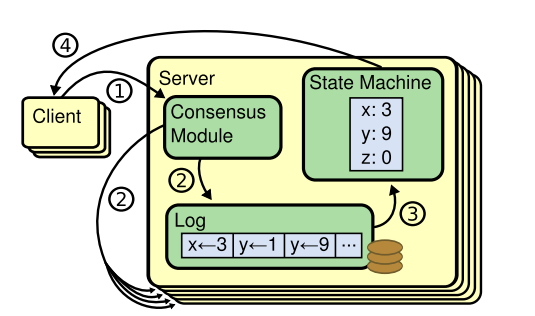
Decompose
为使算法达到可理解性,Raft内部将一致性问题拆解成三个相对独立的子问题
- Leader election
- Log replication
- Safety
Leader election
角色分工
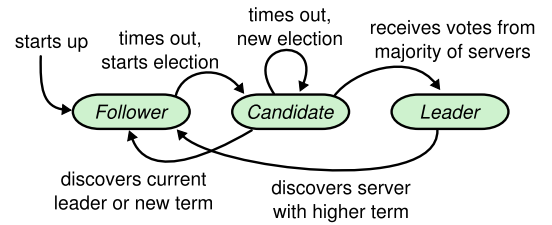
在由Raft协议组织的集群中,每个node存在三种角色:
- Leader
- Candidate
- Follower
每个cluster最多且仅有一个leader来进行管理;
时间被分成很多连续的随机长度的term,可以理解为选举的任期。一个term由一个唯一的id来表示,如下图: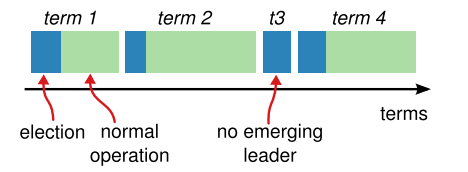
一种term的组成先是成功的选举,接着是由leader管理的时间区间直到该term结束(leader node可能crash,需要重新选举);另一种term的组成是独立的term区间无成功的选举,则需要进行下一个term的操作。
选举流程与细则
- 默认各结点启动后进入follower角色并启动定时器,在timeout时间内没有收到任何通信则进入candidate角色;
- 在candidate角色阶段,发起选举动作,将自身的vote计数加1(自己的一票投给自己),同时向cluster内其他结点广播请求选举消息(RequestVote RPC),并启动选举定时器;
- 在选举定时器timeout前,收到选票数量占大多数(n/2 + 1),则该结点进入leader角色,并通告其他结点; 若在选举定时器timeout时收到选票数量不足大多数,则重启定时器,发起新的选举,此时该结点的term号+1;
- 若某结点在candidate阶段收到leader的通告,则进入follower角色,返回step1;
- 若结点在leader阶段时收到更新的term计数是,则进入follower角色,返回step1;
Split Vote处理
若两个结点同时进入candidate角色,同时发起RequestVote RPC,所获得的选票数量都达不到大多数(选票分散),则双方都退回follower,采用随机timeout时间后再进行选举动作,有效退避,提高选举效率;
当选举结束后,机器内部就有leader进行持续管理,使用heartbeat监控各结点状态。
Log replication
流程
- Client发送command到leader(集群中只有leader可以处理client的请求)
- Leader将command组织到本地的log中,为uncommited状态;
- Leader广播log至Follower,广播log使用AppendEntriesRPC;
- Leader一旦收到大多数的Follower对此log的ACK,则将本地的该条log置成commit状态;返回结果至client;
- Leader通过后续AppendEntriesRPC通知Follower已commit;
- Follower收到commit的log后,将对于的log也commit进StateMachine;
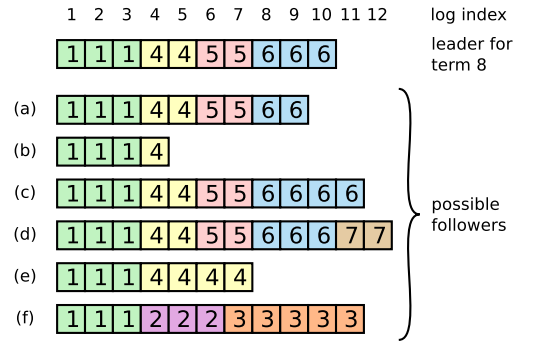
log组成由log index,term,及command组成;
可视化过程: http://thesecretlivesofdata.com/raft/
Safety
Election restriction
- log entries只存在一个方向的流动,即leader to followers;
- 在选举阶段,只有一个拥有比大多数node新的log entires时,即拥有所有commited entires的candidate才能成为leader;
- RequestVote RPC会携带candidate的log信息, 当voter拥有的log信息比requester的log更新时(本地Term更大或者Term一致但是Index更大),会拒绝投票给该candidate;
这样当leader crash了,重新选择leader时会选择cluster中具有更新数据的candidate,这样当leader上线后,通过交互信息,可以将leader中的新log replicate至follower中去,系统中log的流向永远都是leader到follower,当follower中的数据与leader不一致时以leader为准。
Client interaction
当client发起request后,若leader在commit log后响应clien前crash,为解决client重复“刷单”的行为,交互操作应保证“幂等性”来保证数据的准确性。client可以为每个command分配唯一的id来标示此command。leader发现此id对应的command已经commit了,则不需要执行后续操作,直接返回确认即可。
Raft算法在Cluster membership changes 与 Log compaction方面也提供了足够strong的方案,以上诸条能够满足数据在分布式系统中的一致性。
Conclusion
从https://raft.github.io/#implementations中可以看到目前各种主流语言(C/C++,JAVA,PYTHON,GOLANG,ERLANG,JS,RUBY…)都有对raft的实现支持,说明该算法的易理解易实现性,如同论文的结论一样:
算法以正确性、高效性、简洁性作为主要设计目标。
虽然这些都是很有价值的目标,但这些目标都不会达成直到开发者写出一个可用的实现。
所以我们相信可理解性同样重要。