在前面的文章中在介绍virtio机制中,可以看到在通常的应用中一般使用QEMU用户态程序来模拟I/O访问,而Guest中的数据要通过Guest到Host Userspace的第一次拷贝,再经过Host userspace的第二次拷贝,这种多次的数据拷贝和CPU特权级的切换对性能有相当大的影响。为加速virtio设备的I/O性能,VHOST通过driver的形式在Host Kernel中直接实现了virtio设备的模拟。通过在Host Kernel中对virtios设备的模拟运行允许Guest与Host Kernel直接进行数据交换,从而避免了用户空间的system call与数据拷贝的性能消耗。
Vhost的初始化
Qemu层
vhost_net的启用是在命令行的-netdev tap,…中指定vhost=on选项,其初始化流程如下:
- 根据“Qemu之Network Device全虚拟方案一:前端网络流的建立”一文中,tap设备的创建会调用到net_init_tap()函数;
- net_init_tap()其中会检查选项是否指定vhost=on,如果指定,则会调用到vhost_net_init()进行初始化;
- 通过open(“/dev/vhost-net”, O_RDWR)打开了vhost driver;并通过ioctl(vhost_fd)进行了一系列的初始化;
- 调用ioctl VHOST_SET_VRING_KICK 设置kick fd(guest -> vhost) (VirtQueue.host_notifier.fd);
- 调用ioctl VHOST_SET_VRING_CALL 设置call fd(vhost -> guest) (VirtQueue.guest_notifier.fd);
Kernel层
vhost在kernel中是miscdevice的形态存在的:
static const struct file_operations vhost_net_fops = {
.owner = THIS_MODULE,
.release = vhost_net_release,
.unlocked_ioctl = vhost_net_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = vhost_net_compat_ioctl,
#endif
.open = vhost_net_open,
.llseek = noop_llseek,
};
static struct miscdevice vhost_net_misc = {
.minor = VHOST_NET_MINOR,
.name = "vhost-net",
.fops = &vhost_net_fops,
};
static int vhost_net_init(void)
{
if (experimental_zcopytx)
vhost_net_enable_zcopy(VHOST_NET_VQ_TX);
return misc_register(&vhost_net_misc);
}
module_init(vhost_net_init);
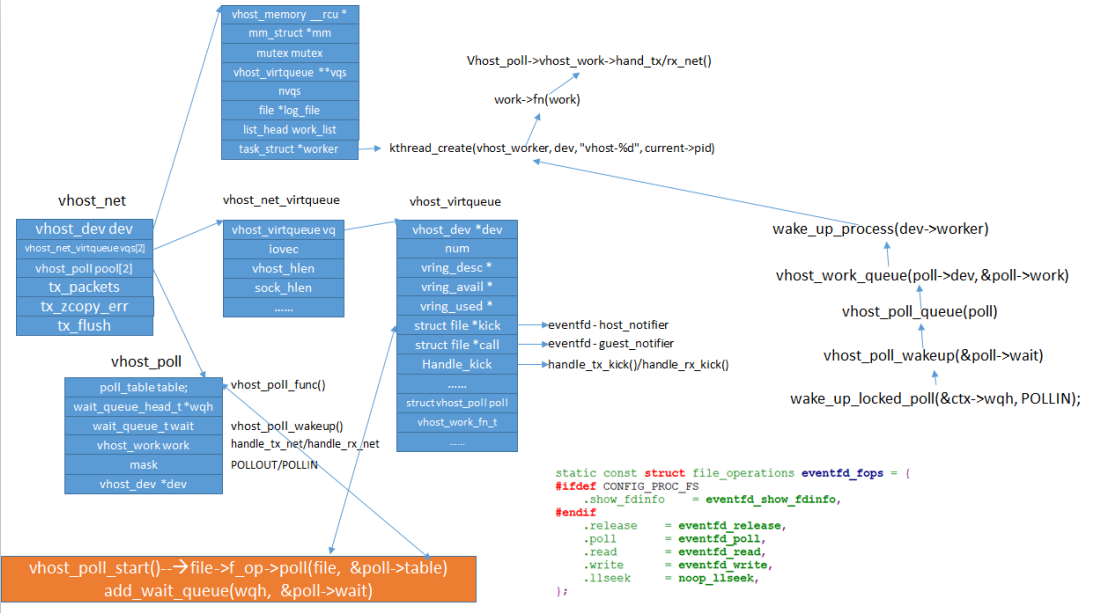
在vhost_net_open()中对vhost进行了初始化,主要数据结构关系如下图:
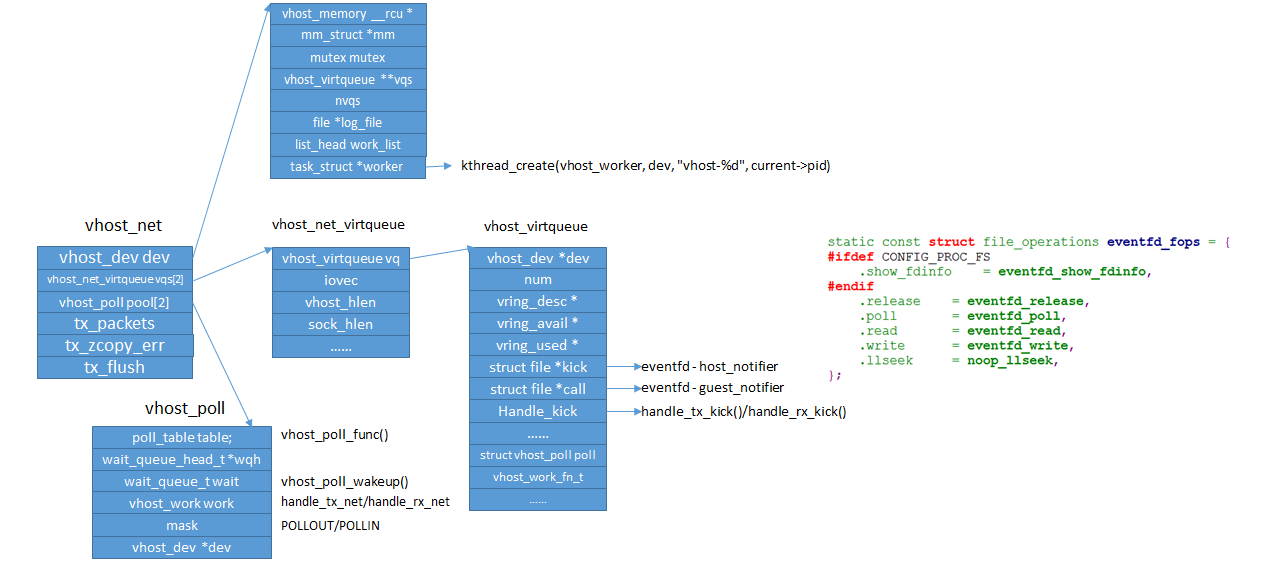
在初始化过程中,vhost driver创建了一个名为“vhost-$pid”内核线程,$pid为Qemu的PID。这个内核线程被称为“vhost worker thread”,该worker thread的任务即为处理virtio的I/O事件。
Guest层
在Guest启动后会调用/drivers/virtio/virtio.c中的virtio_dev_probe进行virtio设备的初始化,
static int virtio_dev_probe(struct device *_d)
{
......
drv->probe(dev);
......
add_status(dev, VIRTIO_CONFIG_S_DRIVER_OK);
......
}
drv->probe()即virtnet_probe(),其中对vq进行了初始化,此过程与前文中的virtio设备正常初始化过程一致,同时将vq的相关信息通告给了前端,Qemu接管后对vq的信息进行了记录,最后Qemu最终调用到vhost_net_start()将vq的配置下发到vhost中:
- ioctl VHOST_SET_VRING_NUM 设置vringsize;
- ioctl VHOST_SET_VRING_BASE 设置 (VirtQueue.last_avail_idx);
- 设置vhost_virtqueue中ring相关的成员(desc,avail, used_size, used_phys, used,
ring_size, ring_phys,ring); - 调用vhost_virtqueue_set_addr设置相关地址;
这样Virtio的vring空间就映射到了Host的Kernel中。
三者之间的关系如下:
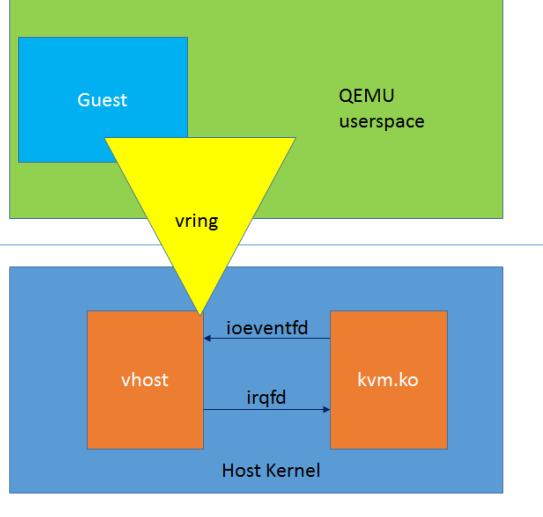
vhost的运行
在上图中可以看到vhost和kvm是两个独立的运行模块,对于Guest来说,vhost并没有模拟一个完整的PCI适配器。它内部只涉及了virtqueue的操作,而virtio设备的适配模拟仍然由Qemu来负责。所以在vhost的整个架构中,其并不是一个完整的virtio设备实现,它依赖于用户空间的管理平面处理,而自身完成位于Host Kernel层的数据面处理。
vhost与kvm的事件通信通过eventfd机制来实现,主要包括两个方向的event,一个是Guest到Vhost方向的kick event,通过ioeventfd承载;另一个是Vhost到Guest方向的call event,通过irqfd承载。
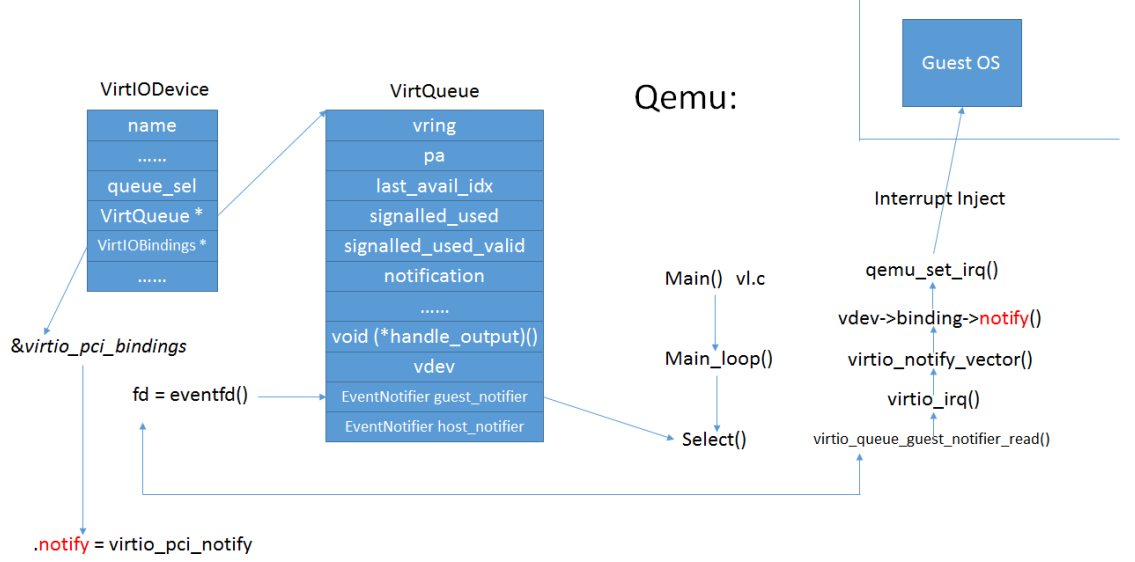
guest_notifier的使用
- vhost在处理完请求(收到数据包),将buffer放到used ring上面之后,往call fd里面写入;
- 如果成功设置了irqfd,则kvm会直接中断guest。如果没有成功设置,则走以下的路径:
- Qemu通过select调用监听到该事件(因为vhost的callfd就是qemu里面对应vq的guest_notifier,它
已经被加入到selectablefd列表); - 调用virtio_pci_guest_notifier_read通知guest;
- guest从used ring上获取相关的数据;
过程如图:
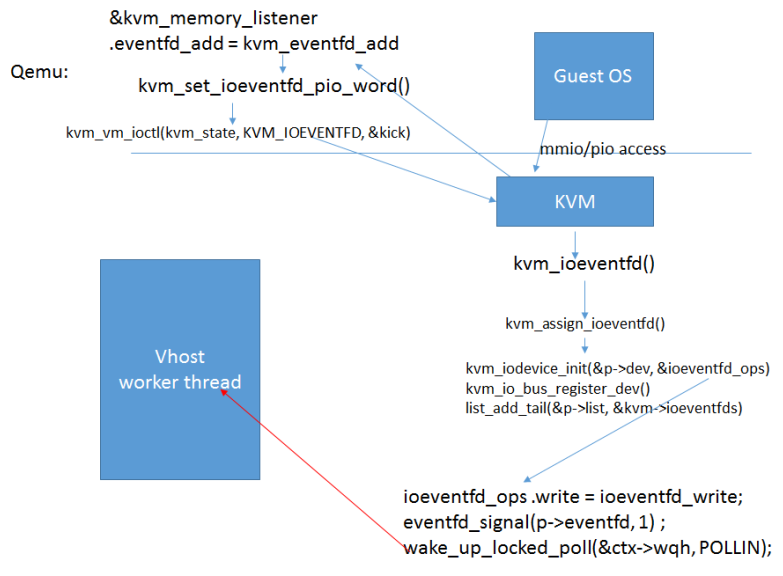
host_notifier的使用
- Guest中的virtio设备将数据放入avail ring上面后,写发送命令至virtio pci配置空间;
- Qemu截获寄存器的访问,调用注册的kvm_memory_listener中的eventfd_add回调函数kvm_eventfd_add
(); - 通过kvm_vm_ioctl(kvm_state, KVM_IOEVENTFD, &kick)进入kvm中;
- kvm唤醒挂载在ioeventfd上vhost worker thread;
- vhost worker thread从avail ring上获取相关数据。
kvm相关流程如图:
vhost中数据结构关系与函数调用流程如下图:
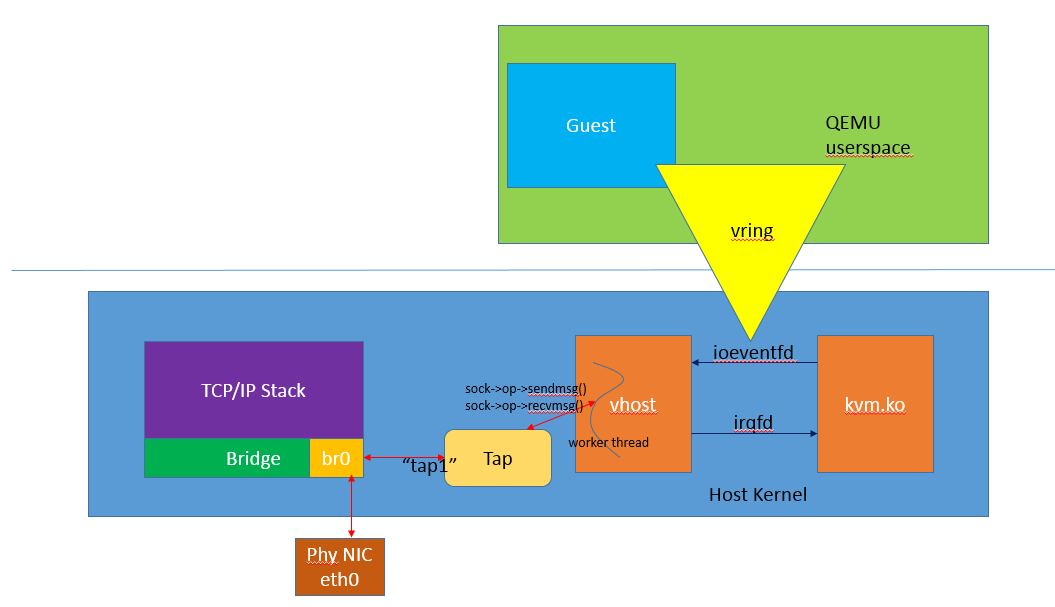
数据发送的完整流程
在上面过程中可以看到vhost最核心处就在于将Guest中的virtio用于传输层的vring队列空间通过mapping方式与Host Kernel进行了共享,这样数据就不需要通过多次的跨态拷贝,直接进入了Kernel;通过io event事件机制进行了收发方向的通告,使vhost与Guest达到很好的配合。
而数据在kernel中最终是如何发送出去的呢?
看如下的图就明白了,在vhost的使能时,我们创建了tap,tap设备的用法和前文介绍的一致,通过加入Bridge来实现数据的交换。而vhost中的数据直接使用tap设备在内核中的sock接口进行了发送和接收,这些动作均是在vhost的worker thread中进行的。
相关code
Kernel相关
- drivers/vhost/vhost.c - common vhost driver code
- drivers/vhost/net.c - vhost-net driver
- virt/kvm/eventfd.c - ioeventfd and irqfd
Qemu相关
- hw/vhost.c - common vhost initialization code
- hw/vhost_net.c - vhost-net initialization