Linux目前支持至少了8种虚拟化系统:
- Xen
- KVM
- VMware’s VMI
- IBM’s System p
- IBM’s System z
- User Mode Linux
- lguest
- IBM’s legacy iSeries
而新的系统也在不断的涌现,各个系统在网络设备、块设备、console及其它设备驱动在新特性支持和性能优化方面存在着瓶颈。
为解决这些问题,Rusty Russell开发了virtio机制,其是一个在hypervisor之上的抽象API接口,让客户机知道自己运行在虚拟化环境中,从而与hypervisor根据virtio标准协作,从而在Guest中达到更好的性能(特别是I/O性能),关于virtio在其论文中如此定义:
virtio:a series of efficient,well-maintained Linux drivers which can be adapted for various different hypervisor implementations using a shim layer.This includes a simple extensible feature mechanism for each driver.
理解: 正如Linux提供了各种hypervisor解决方案,这些解决方案都有自己的特点和优点。这些解决方案包括 Kernel-based Virtual Machine (KVM)、lguest和User-mode Linux等。在这些解决方案中需要各自实现自身平台下的设备虚拟化。而virtio为这些设备模拟提供了一个通用的前端,标准化了接口和增加了代码的跨平台重用。virtio提供了一套有效,易维护、易开发、易扩展的中间层 API,它为 hypervisor 和一组通用的 I/O虚拟化驱动程序提供高效的抽象。减少了各类平台下大量驱动开发的负担。
Virtio的基本架构
QEMU/KVM中,Virtio的基本架构如下图:
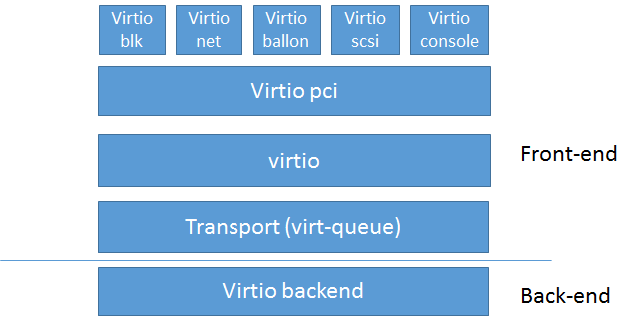
其中前端驱动(front-end,如virtio-blk、virtio-net等)是在Guest中存在的驱动程序模块,而后端处理程序(back-end)是在QEMU中实现的。在这前后端驱动之间,还定义了两层来支持Guest与QEMU之间的通信。其中,“virtio”这一层是虚拟队列接口,它在概念上将前端驱动程序附加到后端处理程序。一个前端驱动程序可以使用0个或多个队列,具体数量取决于需求。例如,virtio-net网络驱动程序使用两个虚拟队列(一个用于接收,另一个用于发送),而virtio-blk块驱动程序仅使用一个虚拟队列。虚拟队列实际上被实现为跨越Guest OS和hypervisor的联系,但它可以通过任意方式实现,前提是Guest OS和virtio后端程序都遵循一定的标准,以相互匹配的方式实现它。
virtio-queue实现了环形缓冲区(ring buffer),用于保存前端驱动和后端处理程序执行的信息,并且它可以批量的方式保存前端驱动的多次I/O请求,并且交由后端去批量处理,减少虚拟运行环境的模式切换,从而提高Guest与hypervisor信息交换的效率。
Virtio设备的创建
1 | qemu-system-x86_64 -net nic,model=? |
通过model = virtio来指定创建virtio的net设备。
Virtio作为一种设备,其也处在Linux的kernel对设备模型的管理之下,先提一下linux kernel的设备模型概念:可以参考我的一篇转载http://blog.csdn.net/hsly_support/article/details/7358941.
Linux设备模型是由总线(bus_type),设备(device),驱动(device_driver)这三大数据结构来描述。在设备模型中,所有的设备都通过总线来连接。即使有些设备没有连接到一根物理上的总线,Linux也为其设置了一个内部的,虚拟的platform总线,来维持总线,驱动,设备三者的关系。总线是处理器与一个或者多个设备之间的通道。比如一个USB控制器通常是一个PCI设备,设备模型展示了总线和他们所控制的设备之间的连接。
总线
Virtio设备为适配Linux Kernel,virtio使用了virtio pcibus类型的虚拟总线。
初始化注册代码如下(file:/drivers/virtio/virtio.c, line:242):1
2
3
4
5
6
7
8
9
10
11
12
13
14static int virtio_init(void)
{
if (bus_register(&virtio_bus) != 0)
panic("virtio bus registration failed");
return 0;
}
static struct bus_type virtio_bus = {
.name = "virtio",
.match = virtio_dev_match,
.dev_groups = virtio_dev_groups,
.uevent = virtio_uevent,
.probe = virtio_dev_probe,
.remove = virtio_dev_remove,
};
驱动
Virtio pci驱动(file: /drivers/virtio/virtio_pci.c,line: 819):1
2
3
4
5
6
7
8
9
10static struct pci_driver virtio_pci_driver = {
.name = "virtio-pci",
.id_table = virtio_pci_id_table,
.probe = virtio_pci_probe,
.remove = virtio_pci_remove,
#ifdef CONFIG_PM_SLEEP
.driver.pm = &virtio_pci_pm_ops,
#endif
};
module_pci_driver(virtio_pci_driver);
设备
Qemu提供了一组virtio设备(file: /hw/virtio-pci.c,line: 1070):1
2
3
4
5
6
7
8static void virtio_pci_register_types(void)
{
type_register_static(&virtio_blk_info); //块设备
type_register_static(&virtio_net_info); //网络设备
type_register_static(&virtio_serial_info); //串行设备
type_register_static(&virtio_balloon_info); //气球
type_register_static(&virtio_scsi_info); //scsi设备
}
当命令行传入virtio时,Qemu会根据注册的virtio_net_info进行virtio net设备的初始化,并在Qemu自身模拟的pci bus层加入了virtio net设备的初始化信息。
当Qemu加载Guest OS后,Guest OS的Bios和Kernel的启动过程中会对Pci设备进行枚举和资源的分配。
当总线类型注册后,/sys/bus/目录下,创建了一个新的目录virtio,在该目录下同时创建了两个文件夹为devices和drivers。表示创建virtio总线,总线支持设备与驱动devices和drivers目录。
对PCI设备进行枚举和资源分配中介绍了,对于枚举的设备,关联到总线链表中。函数pci_register_driver(&virtio_pci_driver)就是对链表的每一个Pci设备进行探测,遍历注册的驱动是否支持该设备,如果支持,调用驱动probe函数,完成启用该Pci设备,同时在virtio总线进行注册设备。
/sys/devices/virtio-pci/创建相应子设备{virtioxxx},同时在/sys/bus/virtio/devices下面创建符号连接文件{virtioxxx}。
virtio netdev
virt net设备除了作为pci设备,同时也是net设备,因此在/drivers/net/virtio-net.c:
static struct virtio_driver virtio_net_driver = {
.feature_table = features,
.feature_table_size = ARRAY_SIZE(features),
.driver.name = KBUILD_MODNAME,
.driver.owner = THIS_MODULE,
.id_table = id_table,
.probe = virtnet_probe,
.remove = virtnet_remove,
.config_changed = virtnet_config_changed,
#ifdef CONFIG_PM_SLEEP
.freeze = virtnet_freeze,
.restore = virtnet_restore,
#endif
};
static int virtnet_probe(struct virtio_device *vdev)
{
struct net_device *dev;
struct virtnet_info *vi;
dev->netdev_ops = &virtnet_netdev; <------------netdev操作函数的注册
SET_ETHTOOL_OPS(dev, &virtnet_ethtool_ops);
SET_NETDEV_DEV(dev, &vdev->dev);
vi = netdev_priv(dev);
vi->dev = dev;
vi->vdev = vdev;
vdev->priv = vi;
/* Use single tx/rx queue pair as default */
vi->curr_queue_pairs = 1;
vi->max_queue_pairs = max_queue_pairs;
/* Allocate/initialize the rx/tx queues, and invoke find_vqs */
err = init_vqs(vi); <----------初始化virt queue
netif_set_real_num_tx_queues(dev, vi->curr_queue_pairs);
netif_set_real_num_rx_queues(dev, vi->curr_queue_pairs);
/*register_netdev的出现,表明向Kernel注册了网络设备类型,对于kernel来讲就可以按照普通网卡来管理*/
err = register_netdev(dev);
/* Last of all, set up some receive buffers. */
for (i = 0; i < vi->curr_queue_pairs; i++) {
try_fill_recv(&vi->rq[i], GFP_KERNEL);
/* If we didn't even get one input buffer, we're useless. */
if (vi->rq[i].vq->num_free ==
virtqueue_get_vring_size(vi->rq[i].vq)) {
free_unused_bufs(vi);
err = -ENOMEM;
goto free_recv_bufs;
}
}
vi->nb.notifier_call = &virtnet_cpu_callback;
err = register_hotcpu_notifier(&vi->nb);
}
virtio netdev操作函数集的定义:
static const struct net_device_ops virtnet_netdev = {
.ndo_open = virtnet_open,
.ndo_stop = virtnet_close,
.ndo_start_xmit = start_xmit,
.ndo_validate_addr = eth_validate_addr,
.ndo_set_mac_address = virtnet_set_mac_address,
.ndo_set_rx_mode = virtnet_set_rx_mode,
.ndo_change_mtu = virtnet_change_mtu,
.ndo_get_stats64 = virtnet_stats,
.ndo_vlan_rx_add_vid = virtnet_vlan_rx_add_vid,
.ndo_vlan_rx_kill_vid = virtnet_vlan_rx_kill_vid,
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = virtnet_netpoll,
#endif
};
这样在qemu和Guest Kernel中对virtio设备的支持下,完成了virtio net设备的初始化,其实该过程与真实物理网卡的初始化过程类似。