前面两文主要对前端网络流的数据路径和虚拟网卡的创建进行了说明,这些可以看做是Guest OS网络数据包收发的准备工作,那么网络数据包是如何在Guest OS中进进出出的呢,本文就是重点讲述Guest OS的数据包的收发路径,其中涉及到一个重要的虚拟化技术,即I/O虚拟化。
Guest OS中网络数据包的接收
前文我们讲到Qemu主线程通过监听Tap设备文件读写事件来收发数据包,当有属于Guest OS的数据包在Host中收到后,Host根据配置通过Bridge,Tap设备来到了Qeumu的用户态空间,Qemu通过调用了预先注册的Tap的读事件处理函数进行处理,如下图:
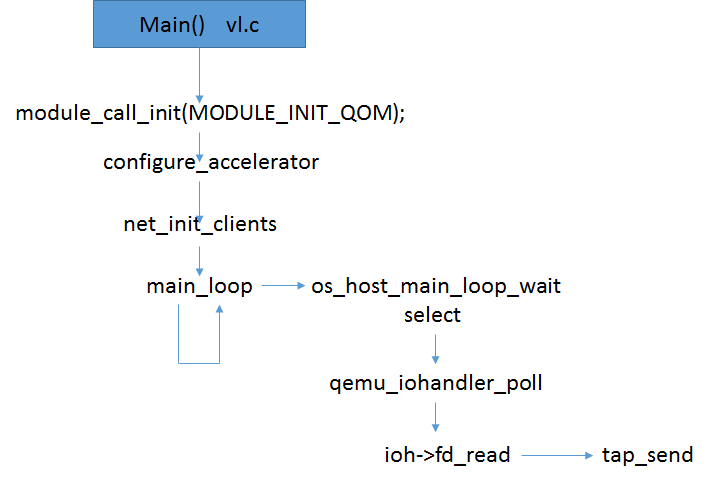
tap_send() file: tap.c, line: 192
tap_read_packet() 通过read从/net/dev/tun的fd中读取数据包
qemu_send_packet_async() file: net.c, line: 384
qemu_send_packet_async_with_flags() file: net.c, line:363
qemu_net_queue_send() file: net.c, line: 170
qemu_net_queue_deliver() file: queue.c, line: 140
qemu_deliver_packet() file: net.c, line: 317
ret = nc->info->receive();
此时的nc->info即为初始化时注册的net_hub_port_info,该结构内容为:
1 | static NetClientInfo net_hub_port_info = { |
我们继续看net_hub_port_receive():
net_hub_port_receive() file: hub.c, line: 108
net_hub_receive() file: hub.c, line: 44
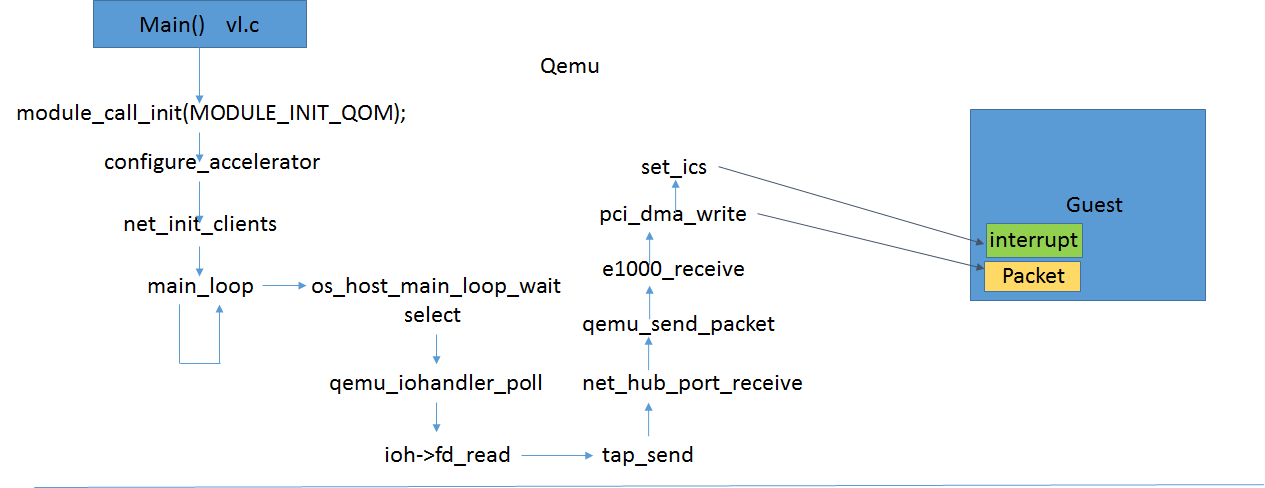
net_hub_receive()这个函数比较有意思,其遍历对应hub下的每个port,通过qume_send_packet()将数据包转发给不是本port的其它port,其实就是vlan环境下二层转发机制。
1 | static ssize_t net_hub_receive(NetHub *hub, NetHubPort *source_port, |
前文最后一图中可以看到,我们配置的该hub或说是vlan下的其它port只有一个就是e1000虚拟网卡,因此qemu_send_packet(&port->nc, buf, len);中的port->nc即e1000的nc结构;继续跟踪数据流向:
qemu_send_packet() file: net.c, line: 392
qemu_send_packet_async() file: net.c, line: 384
qemu_send_packet_async_with_flags() file: net.c, line: 363
qemu_net_queue_send() file: net.c, line: 170
qemu_net_queue_deliver() file: queue.c, line: 140
qemu_deliver_packet() file: net.c, line: 317
ret = nc->info->receive();
这个路径是不是和Tap转发的路径很像,但是这里nc->info并不是net_hub_port_info了,而是e1000创建时注册的net_e1000_info,有疑问的同学可以仔细去看下e1000的初始化流程,这里不过多叙述。看下net_e1000_info中有些什么:
1 | static NetClientInfo net_e1000_info = { |
数据包到达了e1000_receive了:
1 | e1000_receive(NetClientState *nc, const uint8_t *buf, size_t size) |
有上述函数过程的可以看到,数据包从buf中通过pci_dma_write接口注入到了e1000的数据包接收内存中,当然这里的dma并不是真正的硬件DMA操作,而是虚拟化成普通内存的写,因为Guest OS的物理内存是Qemu的虚拟内存,因此Qemu可以直接访问,而Guest并不知道这一切。最后通过set_ics进行Guest收包中断的注入。这一块涉及了中断虚拟化,我们后面单独进行分析。
这样数据包就进入了Guest的物理内存中,收包中断也安排好了,就好像是纯粹的真实的物理网卡到OS的数据流程。而这一切都是全虚拟化应该达到的效果。
Guest OS中网络数据包的发送
当Guest OS中有数据包要发送时,在全虚拟化情况下,Guest会像通常那样走普通网卡驱动流程,将数据包的内容写入待发送的skbuffer的地址空间中,同时将待发送的skbuffer地址放入发送ring中,配置网卡的发送寄存器就可将数据包发送出去,而在Guest模式下,当Guest访问PIO或者MMIO时会触发VM Exit,进入到Host OS 中的kvm。
而设备的模拟是在Qemu中进行的,KVM对该中异常退出无法处理,会将该退出原因注入给Qemu来处理,流程可参考“KVM Run Process之KVM核心流程”一文。
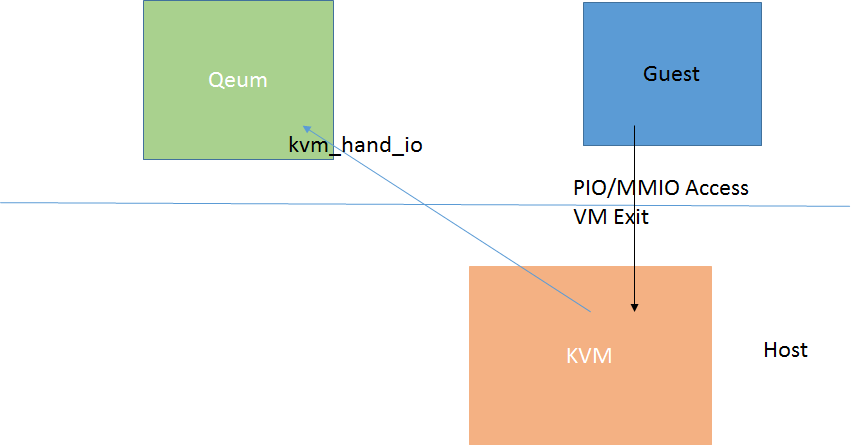
Qemu通过对触发io exit的地址的范围检测,找到对应的PIO/MMIO的地址空间,并调用地址空间注册时的一系列对应寄存器操作处理函数:
1 | static const MemoryRegionOps e1000_mmio_ops = { |
我们这里举个例子就拿[TCTL] = set_tctl发送控制寄存器说事:
set_tctl() file: e1000.c,line: 944
start_xmit() file: e1000.c, line:630
start_xmit()是上面分析的e1000_receive流程相反的一个函数,其将数据包从Guest的物理内存,其实就是Qemu的虚拟内存中读出来,处理一下发送描述符之类的操作,最后发个中断通知下Guest发送情况。这样Guest完全感知不到,认为其在一个真实的环境下完成了收发包处理。
1 | static void start_xmit(E1000State *s) |
从start_xmit到转发到Tap设备,再到Host的bridge发送出去,该路径为接收的反方向,因此不再详细描述。
Conclusion
至此我们看到了全虚拟化方案下,整个数据流的路径是怎么样的。
该路径非常的复杂,其中包含了多次的数据包内存的拷贝,和频繁的虚拟机退出,模式的切换,因此效率是非常低的。